From reports to scan sheets, the need to generate PDF files has been present in every line-of-business application I’ve ever worked on. In the past, I’ve used a variety of tools to achieve this such as SQL Server Reporting Services or Telerik Reporting. While these kinds of tools work well enough for generating reports straight from the database, it’s been surprising how few resources exist to aid in generating PDF files from arbitrary data.
It turns out there is a pretty simple way to enable the generation of PDF files in an ASP.NET MVC application using the same Razor view engine that you’re probably already using. This allows you to make use of view models, HTML helpers, etc. in your PDF logic. The code here is based primarily on the code in MVC itself, specifically the ActionResult and ViewResult classes. It’s also based on general concepts used in two open source projects, MvcRazorToPdf and RazorPDF. In a nutshell, the commands necessary to create a given PDF file (typically as XML) are placed in a standard .cshtml view, rendered and interpreted as any Razor view would be, passed to a PDF generation library (I use the excellent Aspose.Pdf, but this approach can also work with iTextSharp or any other PDF generation library that takes markup such as XML), and then returned to the client as PDF content. This is what the process looks like in a nutshell:
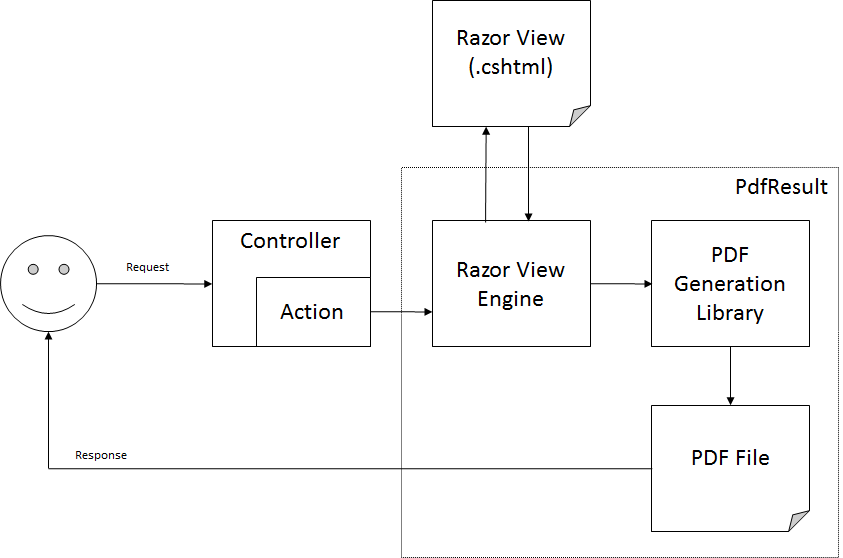
The PdfResult Class
The PdfResult class is the heart of this approach. It contains all of the logic necessary to locate the view, set up the view context, render the view, and generate the PDF file. Though it does all the heavy lifting, there actually isn’t that much code involved:
public class PdfResult : PartialViewResult
{
// Setting a FileDownloadName downloads the PDF instead of viewing it
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
{
throw new ArgumentNullException("context");
}
// Set the model and data
context.Controller.ViewData.Model = Model;
ViewData = context.Controller.ViewData;
TempData = context.Controller.TempData;
// Get the view name
if (string.IsNullOrEmpty(ViewName))
{
ViewName = context.RouteData.GetRequiredString("action");
}
// Get the view
ViewEngineResult viewEngineResult = null;
if (View == null)
{
viewEngineResult = FindView(context);
View = viewEngineResult.View;
}
// Render the view
StringBuilder sb = new StringBuilder();
using (TextWriter tr = new StringWriter(sb))
{
ViewContext viewContext = new ViewContext(context, View, ViewData, TempData, tr);
View.Render(viewContext, tr);
}
if (viewEngineResult != null)
{
viewEngineResult.ViewEngine.ReleaseView(context, View);
}
// Create a PDF from the rendered view content
Aspose.Pdf.Generator.Pdf pdf = new Aspose.Pdf.Generator.Pdf();
using (MemoryStream ms = new MemoryStream(Encoding.UTF8.GetBytes(sb.ToString())))
{
pdf.BindXML(ms, null);
}
// Save the PDF to the response stream
using(MemoryStream ms = new MemoryStream())
{
pdf.Save(ms);
FileContentResult result = new FileContentResult(ms.ToArray(), "application/pdf")
{
FileDownloadName = FileDownloadName
};
result.ExecuteResult(context);
}
}
}
Let’s go through this from top to bottom.
First off, it’s derived from PartialViewResult. Why PartialViewResult and not ViewResult or ActionResult? ViewResult has a more robust implementation of FindView() that looks in several places for the view and includes the convention-based view search logic we’re used to using with normal views. It also includes built-in support for managing the ViewData for a view. So why use PartialViewResult? The reason is that PartialViewResult never attempts to render layouts as part of the view. This is important if you’re using a global layout via a _ViewStart.cshtml file or something similar. Since our PDF file obviously shouldn’t have the same layout logic as one of our actual web pages, we need to make sure that doesn’t get included in the rendered PDF syntax. The easiest way to do that is to derive our PdfResult class from PartialViewResult, which ensures a layout is not used by returning a slightly different ViewEngineResult (and thus IView) in it’s own FindView() implementation.
Looking at the body, the only method is an override of ExecuteResult(). This method is called when the PdfResult (or any ActionResult) is processed by MVC and is intended to manipulate the result sent to the client (by adding content, setting headers, etc.). The first thing we do is check to make sure we have a context. This block, and most of the rest of the first part of the method, is copied straight from the implementation in MVC. Next we set the model (if there is one) and the other data that will be passed to the view. This is necessary to make sure that when we interpret our view code we have access to all of the same kinds of data we would have if this were just a normal web view. Then we get the name of the view from the action name if a view name wasn’t already provided. We set this in the ViewName member which FindView() uses to locate the view.
This is where things get a little bit interesting. Next we call FindView() which locates the actual view .cshtml file using MVC conventions and instantiates an IView for us that can be used for rendering the view. We then create a ViewContext to hold all of the data our view might need and call the Render() method of the IView we were previously provided. This triggers the Razor view engine and is where the view magically gets transformed into content we can pass to our PDF generation library.
Once we have the content to pass to the PDF generator library, we create the PDF file. The code above is written for Aspose.Pdf, but could be adapted to work with iTextSharp like this (from MvcRazorToPdf):
// Create a PDF from the rendered view content
var workStream = new MemoryStream();
var document = new Document();
PdfWriter writer = PdfWriter.GetInstance(document, workStream);
writer.CloseStream = false;
document.Open();
Stream stream = new MemoryStream(Encoding.UTF8.GetBytes(sb.ToString()));
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, stream, null);
document.Close();
// Save the PDF to the response stream
FileContentResult result = new FileContentResult(workStream.ToArray(), "application/pdf")
{
FileDownloadName = FileDownloadName
};
One final note about the FileDownloadName property and it’s use in the FileContentResult. If null is supplied for FileDownloadName, the PDF file will be delivered to the browser and rendered inline. However, if a value is supplied for FileDownloadName, the browser will initiate a file download of a PDF file with that name. This lets you control the way in which the client views and downloads the PDF file.
The Controller
Now that we have the PdfResult class complete, how do we use it to actually generate a PDF file? This step is optional, but I prefer to add a method to my Controller base class to support alternate view results from an action. The base Controller in MVC already does this – you typically write return View(); not return new ViewResult() { ... }; If you don’t already have a custom base Controller in your MVC application, I suggest adding one. Even if it’s just to hold the next bit of code, it’s worthwhile. And I’ve found over time that it’s nice having a base Controller class into which I can add all sorts of other helper methods and additional logic. To that end, the following are overloads for a Pdf() method that can be used as the return value for an action:
protected ActionResult Pdf()
{
return Pdf(null, null, null);
}
protected ActionResult Pdf(string fileDownloadName)
{
return Pdf(fileDownloadName, null, null);
}
protected ActionResult Pdf(string fileDownloadName, string viewName)
{
return Pdf(fileDownloadName, viewName, null);
}
protected ActionResult Pdf(object model)
{
return Pdf(null, null, model);
}
protected ActionResult Pdf(string fileDownloadName, object model)
{
return Pdf(fileDownloadName, null, model);
}
protected ActionResult Pdf(string fileDownloadName, string viewName, object model)
{
// Based on View() code in Controller base class from MVC
if (model != null)
{
ViewData.Model = model;
}
PdfResult pdf = new PdfResult()
{
FileDownloadName = fileDownloadName,
ViewName = viewName,
ViewData = ViewData,
TempData = TempData,
ViewEngineCollection = ViewEngineCollection
};
return pdf;
}
The Action
The result of all this is that you can write you PDF generating actions in a very similar way to how you write your normal web actions:
public virtual ActionResult PdfTest()
{
return Pdf(new int[] { 1, 2, 3 });
}
The code about will cause a PdfResult class to be instantiated which will attempt to find a view named “PdfTest.cshtml” in the conventional location. It will be given an int[] array as it’s model and then rendered by the Razor view engine.
The View
The final step is the view, where the actual PDF content is specified. Recall that I said I’m using Aspose.Pdf, so the XML in my view corresponds to the XML that Aspose.Pdf expects. If you’re using iTextSharp or any other PDF generation library then the XML (or other type of) content contained in your view may look drastically different. But for the sake of example, here’s what a sample view might look like using the Aspose.Pdf XML format:
@model IEnumerable<int>
<Pdf xmlns="Aspose.Pdf" DestinationType="FitPage">
<Section>
@foreach (int c in Model)
{
@:<Text Alignment="Center"><Segment>@c</Segment></Text>
}
</Section>
</Pdf>
The Razor syntax checker in Visual Studio will probably complain that all these XML elements are not valid HTML5 (or whatever other validation type you have configured), but that’s fine – the actual view engine will deal with them without issue. One small complication you’ll see above is that the Aspose.Pdf XML specification uses an element called Text. Unfortunately, this element also has a very special meaning in Razor syntax. We need to escape it when used directly inside a code block by using @:.
Conclusion
That about covers it. This was a pretty long article, mainly because I wanted to explain how everything fit together. Hopefully you’ll see that when you get right down to it the approach is actually pretty simple. Now go forth and populate your web apps with lots of useful PDF documents.