The most recent version of Nxdb includes a complete object persistence framework and this post explains some of the motivation behind it and provides some insight into how it was implemented.
What Is A Persistence Framework?
Wikipedia sums it up nicely by saying "a persistence framework is middleware that assists and automates the storage of program data into databases." More to the point, a persistence framework allows the state of object instances to be stored externally (usually, but not necessarily, in a database) and recalled at a later time (such as a future program execution). The "state" of an object could be everything that is necessary to fully represent the object (such as all of it's fields), or it could be some important subset of object data.
Persistence frameworks are related to, but not the same, as object-relational mapper (ORM) tools. A persistence framework usually manages the conversion of an object to some format the external storage medium can understand, the storage of that data into the external medium, the fetching of data from the external medium, and the instantiation and population of instances based on that data. The problem with persistence frameworks when they use a relational database (or other highly structured storage) is that the database needs to know something about the objects being stored so that tables, columns, etc. can be created to support them. ORM tools assist with this process by mapping the data to be stored (I.e., the object) to the storage medium (I.e., the database). They often automate the process of creating appropriate tables and columns, managing foreign keys, etc. An ORM is only needed when the storage medium cannot natively support the type or structure of data needing to be stored.
Why Create A New Persistence Framework?
In general, I wouldn't really recommend rolling your own persistence framework. There are so many good ones out there (including NHibernate, SubSonic, and mybatis) and it is doubtful you'll be able to improve on them enough to make the exercise worthwhile. So why ignore this advice and build a new one for Nxdb? The answer is that almost all of the existing persistence framework are based on SQL, talk to SQL databases, and either use or have built-in ORM capabilities. XML is a completely different storage medium, one that is able to better represent the hierarchical nature of object-oriented classes. While a couple of .NET XML persistence frameworks do exist (such as Proetus) and several articles have been written at CodeProject and elsewhere on how to write XML persistence capabilities, they tend to be somewhat conceptual and abstract the storage layer by producing XML that becomes the developer's responsibility to store and retrieve. We saw an opportunity to unlock the potential of a native XML persistence layer by having it be tied directly to an XML database. This allows automation of the storage and retrieval of objects and opens up the door for interesting use cases such as querying the object graph using XQuery.
Requirements
When we started thinking about an XML persistence layer for Nxdb we considered what the most important requirements should be and narrowed them down to a few key ones:
- The framework should be able to serialize objects in a variety of ways to support many different environments and uses.
- The framework should automate the process of storing and fetching objects as much as possible.
- The framework should require as small a change as possible to existing objects to make them compatible.
- The framework should be extensible, allowing developers to modify or enhance any aspect of the design.
Overall Design
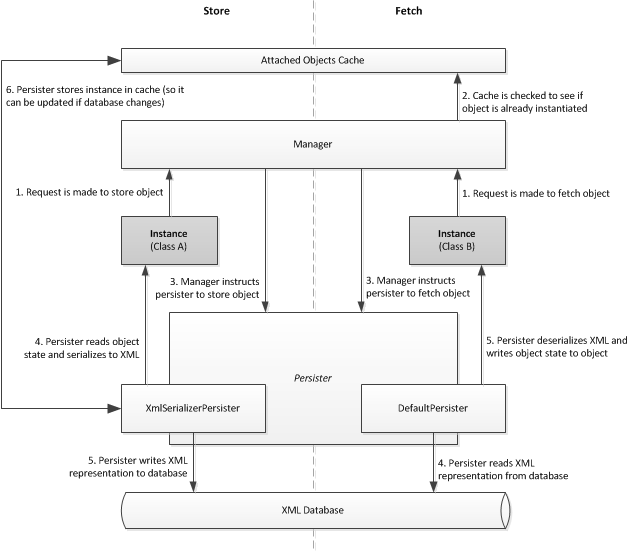
The main entry point for the persistence framework is the Manager class. All objects are initially persisted or retrieved through one of it's methods. Objects can be attached to the manager, which means that they are stored in a cache and the manager will return a reference to the same instance of the object if the same XML content is used. Additionally, attached objects can be automatically updated when the database changes, making the objects more of a programmatic representation of the database rather than the database simply serving as a backing store. Each object is persisted to and from the database using a Persister. The persister is primarily responsible for determining what parts of an object should be stored in the database, how those parts should be represented (for example as XML elements or attributes), and performing the actual serialization and deserialization of an object. There are several persisters including one that supports the native .NET XmlSerializer, one that provides a great deal of control through the use of attributes on class members, and one that allows completely custom behavior through the implementation of an interface. Should additional techniques be required, a new persister is easy to create and implement. Overall, the architecture and process by which objects are stored to the database and fetched from the database is presented below.